
Karol Przystalski, Jan K. Argasiński, Iwona Grabska-Gradzińska, Jeremi K. Ochab
A recent study co-authored by Jan K. Argasiński from the Computational Neuroscience group at the Sano Centre for Computational Medicine investigates the potential of stylometry — a technique traditionally applied in authorship attribution — to differentiate between human-written content and texts produced by Large Language Models (LLMs).
The researchers developed a benchmark dataset sourced from Wikipedia, featuring:
- Summaries authored by humans
- Summaries generated by various LLMs (GPT-3.5/4, LLaMa 2/3, Orca, Falcon)
- Summaries altered by automatic summarisation tools (T5, BART, Gensim, Sumy)
- Texts reworded using paraphrasing systems (Dipper, T5)
By applying decision trees and LightGBM classifiers, and incorporating both manually crafted features (via the StyloMetrix toolkit) and n-gram-based stylometric indicators, the models achieved notable results:
- Up to 0.87 Matthews correlation coefficient (MCC) in a multi-class (7-way) classification task
- Between 0.79 and 1.0 accuracy in binary classification, with detection of GPT-4 texts reaching 98% accuracy on balanced datasets
Interpretability analysis showed that LLM-generated texts tend to be more grammatically uniform and exhibit distinctive lexical patterns compared to human writing. These findings demonstrate that, despite the growing sophistication of AI-generated text, distinguishing between machine and human authorship remains feasible — especially for structured formats like encyclopaedia entries.
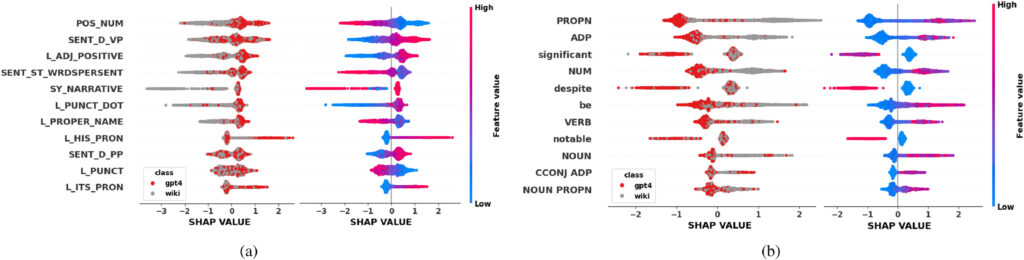
Fig. 1. Explanations for binary classification between the Wikipedia and GPT-4.
Source: www.sciencedirect.com/science/article/pii/S0957417425026181#fig0002
READ HEREStylometry recognizes human and LLM-generated texts in short samples
Authors: Karol Przystalski, Jan K. Argasiński, Iwona Grabska-Gradzińska, Jeremi K. Ochab
DOI: 10.1016/j.eswa.2025.129001